
6分钟获取"天天麻将其实向来真的有挂!"其实有挂猫腻(2024有挂版)
6分钟获取"天天麻将其实向来真的有挂!"其实有挂猫腻(2024有挂版)亲,[天天麻将]这款游戏可以开挂的,确实是有挂的,。但是开挂要下载第三方辅助软件,天天麻将的开挂软件,名称叫天天麻将开挂软件。方法如下:网上搜索天天麻将开挂软件,跟对方讲好价格,进行交易,购买第三方开发软件。通过添加客服微信【485275054】安装软件;

一、私人局和透视挂机的基本概念
- 私人局:天天麻将 的私人局是指玩家之间自行建立的游戏房间,通常在私人局中,只有事先邀请的好友才能参与游戏,这样能够确保游戏的隐私性和友好性。
- 透视挂机:透视挂机声称能够让玩家在游戏过程中看到其他玩家的手牌,从而获得巨大的优势。这种软件声称能够突破游戏的保密措施,让使用者事先知道其他玩家的牌,并且在游戏中无往不利。
二、透视挂机是否真实存在?
- 天天麻将 官方态度:作为一家有声誉的棋牌游戏平台,天天麻将 一直致力于维护游戏的公平性和安全性。根据官方的声明,天天麻将 严厉打击任何违规行为,包括使用外挂软件等非法手段获得不正当优势。因此,天天麻将 官方对于透视挂机是零容忍的,会积极封禁使用此类软件的账号。
- 技术原理解析:尽管 天天麻将 官方对透视挂机持否定态度,但是一些不法分子仍会尝试通过各种手段制作透视挂机软件。但需要明确的是,天天麻将 的游戏系统是经过严格设计和测试的,为了保障游戏的公平性,很多关键数据都是在服务器端进行处理的,而不是在客户端。
可能的透视挂机技术原理包括:
a. 代理服务器欺骗:一些透视挂机软件声称通过中间代理服务器获取游戏数据,然后对数据进行解析,以获取其他玩家的手牌信息。然而,天天麻将 的服务器会通过加密和认证措施来防止此类行为,以保护玩家的信息安全。
b. 屏幕截图识别:另一种可能性是通过屏幕截图识别手牌。但这种方法有很多技术难题,包括对图像的处理速度、精准度等要求非常高,而且很容易被游戏防作弊机制察觉。
c. 数据包拦截:一些软件声称通过拦截游戏数据包来获取手牌信息。但现代棋牌游戏通常会对数据包进行加密和校验,以防止此类干扰,同时服务器也会进行数据包分析,确保玩家之间的数据交换是合法的。
三、保障私人局游戏公平性的措施
天天麻将 采取了多重措施来保障私人局游戏的公平性和安全性:
- 加密保护:天天麻将 使用了高强度的加密技术,确保游戏数据在传输过程中不易被篡改和窃取。
- 服务器验证:关键游戏数据处理和验证是在服务器端进行的,避免了客户端数据的干预,确保了游戏的公平性。
- 举报和封禁:天天麻将 设有专门的举报机制,玩家可以举报可疑行为。官方会进行调查,并对使用外挂软件的账号进行封禁处理。
结论:尽管一些声称能够透视私人局的挂机软件存在,但 天天麻将 官方对此持绝对零容忍的态度,并采取了多种技术手段来保障游戏的公平性和玩家的权益。玩家应该通过官方渠道下载游戏,避免使用不明来源的第三方软件,以确保自己的账号安全。同时,若发现可疑行为,应积极举报,共同维护良好的游戏环境。
今天凌晨两点,OpenAI开启了12天技术分享直播,发布了最新“强化微调”(Reinforcement Fine-Tuning)计划。
与传统的微调相比,强化微调可以让开发者使用经过微调的更强专家大模型(例如,GPT-4o、o1),来开发适用于金融、法律、医疗、科研等不同领域的AI助手。
简单来说,这是一种深度定制技术,开发者可利用数十到数千个高质量任务,参照提供的参考答案对模型响应评分,让模型学习如何就类似问题推理,提高其在特定领域任务上的准确性和工作效率。

申请API:https://openai.com/form/rft-research-program/
在许多行业,虽然一些专家具有深厚的专业知识和丰富的经验,但在处理大规模数据和复杂任务时,可能会受到时间和精力的限制。
例如,在法律领域,律师需要处理大量的法律条文和案例,虽然他们能够凭借专业知识进行分析,但借助经过强化微调的 AI 模型,可以更快速地检索相关案例、进行初步的法律条文匹配和分析,为律师提供决策参考,提高工作效率。
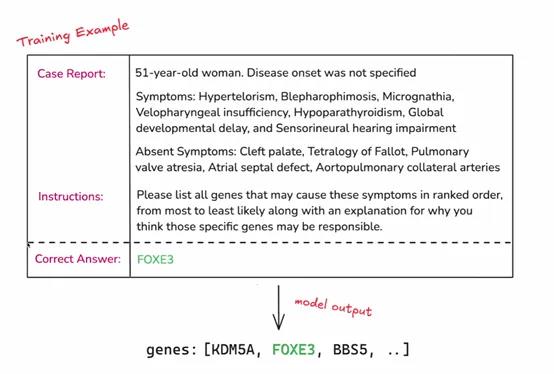
OpenAI表示,作为研究计划的一部分,参与者将能够访问处于alpha 阶段的强化微调 API。开发者可以利用该 API 将自己领域特定的任务数据输入到模型中,进行强化微调的实验和应用。
例如,一家医疗研究机构可以将大量的临床病例数据通过 API 输入到模型中,对模型进行医疗诊断任务的强化微调,使其能够更好地理解和处理各种疾病症状与诊断之间的关系。
目前该 API 仍处于开发阶段,尚未公开发布。所以,参与者在使用 API 过程中遇到的问题、对 API 功能的建议以及在特定任务上的微调效果等反馈,对于 OpenAI 改进 API 具有至关重要的作用。
例如,企业在使用 API 对其财务风险评估模型进行微调时,如果发现模型在处理某些特殊财务数据结构时出现错误或不准确的情况,将这些信息反馈给 OpenAI,能够帮助其优化 API 中的数据处理算法和模型参数调整策略,从而使 API 更加完善,为后续的公开发布做好准备。
强化微调简单介绍
强化微调是一种在机器学习和深度学习领域,特别是在大模型微调中使用的技术。这项技术融合了强化学习的原理,以此来优化模型的性能。微调是在预训练模型的基础上进行的,预训练模型已经在大量数据上训练过,学习到了通用的特征。
通过无监督学习掌握了语言的基本规律,然后在特定任务上进行微调,以适应新的要求。强化学习则关注智能体如何在环境中采取行动以最大化累积奖励,这在机器人训练中尤为重要,智能体通过不断尝试和学习来找到最优策略。
强化微调则是将强化学习的机制引入到微调过程中。在传统微调中,模型参数更新主要基于损失函数,而在强化微调中,会定义一个奖励信号来指导这个过程。
这个奖励信号基于模型在特定任务中的表现,比如在对话系统中,模型生成的回答如果能够引导对话顺利进行并获得好评,就会得到正的奖励。策略优化是利用强化学习中的算法,如策略梯度算法,根据奖励信号来更新模型参数。
在这个过程中,模型就像智能体一样,它的参数调整策略就是需要优化的策略,而奖励信号就是对这个策略的评价。
此外,强化微调还需要平衡探索和利用,即模型既要利用已经学到的知识来稳定获得奖励,又要探索新的参数空间以找到更优的配置。
收集人类反馈数据,通常是关于模型输出质量的比较数据。通过这些反馈训练一个奖励模型,该模型能够对语言模型的输出进行打分,以反映其质量或符合人类期望。