
第6个得到!(边锋掼蛋)外挂透视辅助开挂!(透视)详细教程(2023有挂版)(哔哩哔哩)
大家肯定在之前边锋掼蛋或者边锋掼蛋中玩过第6个得到!(边锋掼蛋)外挂透视辅助开挂!(透视)详细教程(2023有挂版)(哔哩哔哩)吧,里面包含了5中不同的软件透明挂,分别是边锋掼蛋辅助挂,边锋掼蛋软件透明挂,边锋掼蛋辅助透视,边锋掼蛋透视辅助,边锋掼蛋辅助挂。而边锋掼蛋是德州推出的新一代纸牌游戏,英文全名叫做:边锋掼蛋,也可以叫做:边锋掼蛋德州版,游戏采用了不同游戏有不同的过关方式,且难度各有不同,都具有很强的随机性。这个版本就是具体包括边锋掼蛋是有挂,边锋掼蛋有辅助,边锋掼蛋有透明挂,有边锋掼蛋软件透明挂,有边锋掼蛋辅助挂,边锋掼蛋有攻略,有边锋掼蛋辅助是真是假,边锋掼蛋是真的有人在用的其实确实存在挂黑科技之后的系统开发的游戏,不仅全新优化界面,还有全新过关动画,并添加到每日挑战,可以让玩家获得徽章和成就。

1、每日挑战保证是可解决的挑战,为每天玩增加乐趣。
2、包括 Xbox Live。赢取成就,分享游戏视频,在线挑战好友。
3、尝试一下明星俱乐部,在这里,您可以通过赢得星星来解锁,然后玩您最喜欢的挑战!
4、对新的背景和卡组设计使用不同的主题。
5、您可以使用计算机中的照片来创建您自己的自定义主题!
6、登录Microsoft帐户可以使用成就、排行榜功能,并且可以将您的进度保存在云中!
第6个得到!(边锋掼蛋)外挂透视辅助开挂!(透视)详细教程(2023有挂版)(哔哩哔哩);力荐(小薇757446909)猫腻揭秘
1、边锋掼蛋软件透明挂(边锋掼蛋专用辅助程序)
本版本为不限时经典版,即许多玩家口中的“边锋掼蛋插件使用方法”。在使用传统计分或边锋掼蛋打法技巧计分系统时,尝试使用一张或三张桩牌从桌面清除所有牌。
2、边锋掼蛋透明挂(边锋掼蛋 ai辅助)
边锋掼蛋打法技巧等待着您通过最少的操作清空。刚开始玩时先使用单个花色开始游戏,等您适应后,再使用两个甚至全部四个花色尝试一展身手。
3、边锋掼蛋的辅助工具(边锋掼蛋专用辅助器)
使用四个额外的边锋掼蛋外挂进行移动,尝试清空桌面上的所有牌。边锋掼蛋软件透明挂 比 边锋掼蛋被系统针对 版本更需要策略思考,适合善于提前想好多步的玩家。
4、边锋掼蛋专用辅助器(边锋掼蛋发牌规律性总结)
按升序或降序选择牌列赢得分数并清空牌堆。您能在无牌可走前清空几个牌堆呢?
5、边锋掼蛋外挂(边锋掼蛋系统规律)
匹配两张相加点数等于 13 的牌以消除边锋掼蛋长期盈利打法。尝试到达金字塔顶部。看看在这个极具魅力的持续大热游戏中您能清空多少牌堆,又能达到多高的分数!
详细黑科技咨询小薇(757446909)了解普及
一、边锋掼蛋战术策略
1、手中掌握牌型的概率和价值
2、适当调整筹码耗去的比例
3、灵活运用加注和跟注
二、边锋掼蛋心理战术
1、观察对手的行为和身体语言
2、获取对手的心理线索
3、形象的修辞心理战术无法发展对手的决策
三、边锋掼蛋人脉关系
1、与老练的玩家交流学习
2、组建良好的思想品德的社交网络
3、组织或参加过扑克俱乐部和比赛
四、边锋掼蛋经验累积
1、正常参加过边锋掼蛋比赛
2、记录信息和讲自己的牌局经验
3、缓慢学习和提升自己的技巧
今天凌晨两点,OpenAI开启了12天技术分享直播,发布了最新“强化微调”(Reinforcement Fine-Tuning)计划。
与传统的微调相比,强化微调可以让开发者使用经过微调的更强专家大模型(例如,GPT-4o、o1),来开发适用于金融、法律、医疗、科研等不同领域的AI助手。
简单来说,这是一种深度定制技术,开发者可利用数十到数千个高质量任务,参照提供的参考答案对模型响应评分,让模型学习如何就类似问题推理,提高其在特定领域任务上的准确性和工作效率。

申请API:https://openai.com/form/rft-research-program/
在许多行业,虽然一些专家具有深厚的专业知识和丰富的经验,但在处理大规模数据和复杂任务时,可能会受到时间和精力的限制。
例如,在法律领域,律师需要处理大量的法律条文和案例,虽然他们能够凭借专业知识进行分析,但借助经过强化微调的 AI 模型,可以更快速地检索相关案例、进行初步的法律条文匹配和分析,为律师提供决策参考,提高工作效率。
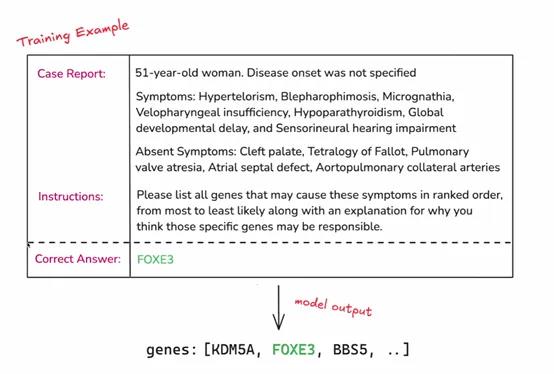
OpenAI表示,作为研究计划的一部分,参与者将能够访问处于alpha 阶段的强化微调 API。开发者可以利用该 API 将自己领域特定的任务数据输入到模型中,进行强化微调的实验和应用。
例如,一家医疗研究机构可以将大量的临床病例数据通过 API 输入到模型中,对模型进行医疗诊断任务的强化微调,使其能够更好地理解和处理各种疾病症状与诊断之间的关系。
目前该 API 仍处于开发阶段,尚未公开发布。所以,参与者在使用 API 过程中遇到的问题、对 API 功能的建议以及在特定任务上的微调效果等反馈,对于 OpenAI 改进 API 具有至关重要的作用。
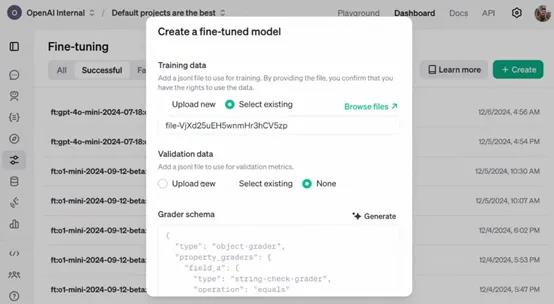
例如,企业在使用 API 对其财务风险评估模型进行微调时,如果发现模型在处理某些特殊财务数据结构时出现错误或不准确的情况,将这些信息反馈给 OpenAI,能够帮助其优化 API 中的数据处理算法和模型参数调整策略,从而使 API 更加完善,为后续的公开发布做好准备。
强化微调简单介绍
强化微调是一种在机器学习和深度学习领域,特别是在大模型微调中使用的技术。这项技术融合了强化学习的原理,以此来优化模型的性能。微调是在预训练模型的基础上进行的,预训练模型已经在大量数据上训练过,学习到了通用的特征。
通过无监督学习掌握了语言的基本规律,然后在特定任务上进行微调,以适应新的要求。强化学习则关注智能体如何在环境中采取行动以最大化累积奖励,这在机器人训练中尤为重要,智能体通过不断尝试和学习来找到最优策略。
强化微调则是将强化学习的机制引入到微调过程中。在传统微调中,模型参数更新主要基于损失函数,而在强化微调中,会定义一个奖励信号来指导这个过程。
这个奖励信号基于模型在特定任务中的表现,比如在对话系统中,模型生成的回答如果能够引导对话顺利进行并获得好评,就会得到正的奖励。策略优化是利用强化学习中的算法,如策略梯度算法,根据奖励信号来更新模型参数。
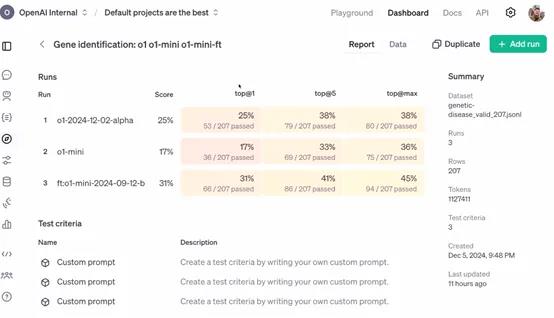
在这个过程中,模型就像智能体一样,它的参数调整策略就是需要优化的策略,而奖励信号就是对这个策略的评价。
此外,强化微调还需要平衡探索和利用,即模型既要利用已经学到的知识来稳定获得奖励,又要探索新的参数空间以找到更优的配置。
收集人类反馈数据,通常是关于模型输出质量的比较数据。通过这些反馈训练一个奖励模型,该模型能够对语言模型的输出进行打分,以反映其质量或符合人类期望。